Why You Should Simplify And Automate Before Your Next Hire
There's a common sequence of events in growing businesses: the team gets busy, someone can't keep up, so you hire …

Two AI models produced the same passing meal plan for the same test households. One model cost 30x less than the other, while being 2.5x faster.
The surprise isn't that the cheap model won - it's that we could only see it because we'd already decided, in writing, what "a good plan" meant.
One of the use cases that tests Nornilo's capabilities is Madklar, an AI-supported meal-planning app for busy families.
Every plan the user sees is generated by an LLM picking a week's worth of dinners from a household's profile and preferences, available ingredients in the pantry, and recent history.
Which LLM, though? "Try a few and see" doesn't scale, especially when prices and capabilities shift so fast. So we built a small shootout - a controlled, reproducible way to compare models on the actual task.
The first thing we had to write was a contract: what does "a good plan" actually mean?
If I can't decide that before any model runs, I can't compare them.
The contract for make_meal_plan v0.5 is one JSON file output with
eight hard rules and four soft scorers. Hard rules are pass/fail:
Soft scorers are 0.0–1.0 and just get logged:
The contract is the testable version of "a good plan." Everything else flows from it - the validators implement it, the runner calls models against it, the dashboard renders pass-rates against it.

Real household data is a privacy minefield. So we built three synthetic ones for a start, plus our own:
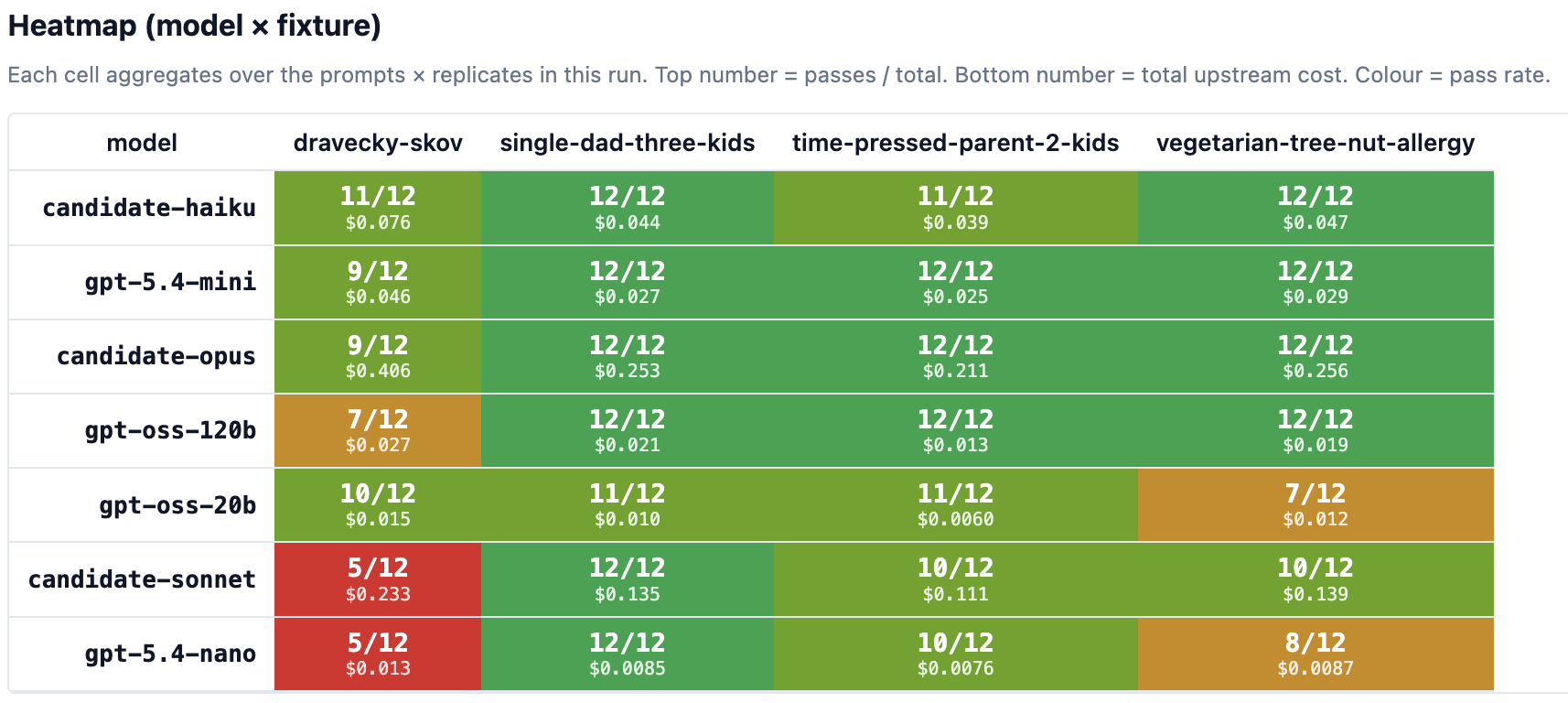
The dravecky-skov household is the one no model could solve in the v0.5 sweep. That's the point: solving the easy cases doesn't prove we can succeed in real life.
The first run included 7 AI models provided by Cloudflare AI Workers. We ran it on all four households, three replicates per cell. 84 calls, about 25 minutes wall time.
The headline: no model solved the dravecky-skov problem in the first
sweep. Every candidate ran into something - markdown fences around the
JSON, cooking for six on a day when only three were home, or suggesting
cheese to lactose-free members.
The best model solved only 50% of cases successfully, with a median latency of 15 seconds per plan. Some were much worse.
I was getting worried: if we couldn't move this number significantly, Madklar would never take off.
For v0.6 we focused on the hardest household, the two best models from v0.5, and one question: is the failure a model problem or a prompt problem? We wrote nine variants - terse, schema-first, few-shot, constraint-first, fence-warning, OpenAI's literal small-model style, a hidden attendance ledger, and a "validator-mirror" that read back the hard rules.
Three findings did most of the work:
Once we added GPT-5.4-mini and Claude Haiku on the AI router's menu, we extended the sweep to four models. Then we added seven more candidates from Cloudflare's Workers AI menu. By the end we had 78 cells across 11 models.
The next precision pass was bigger and cleaner: 336 calls across four households, four prompt variants, seven models, and three replicates per cell. It produced 290 passes and one upstream error.
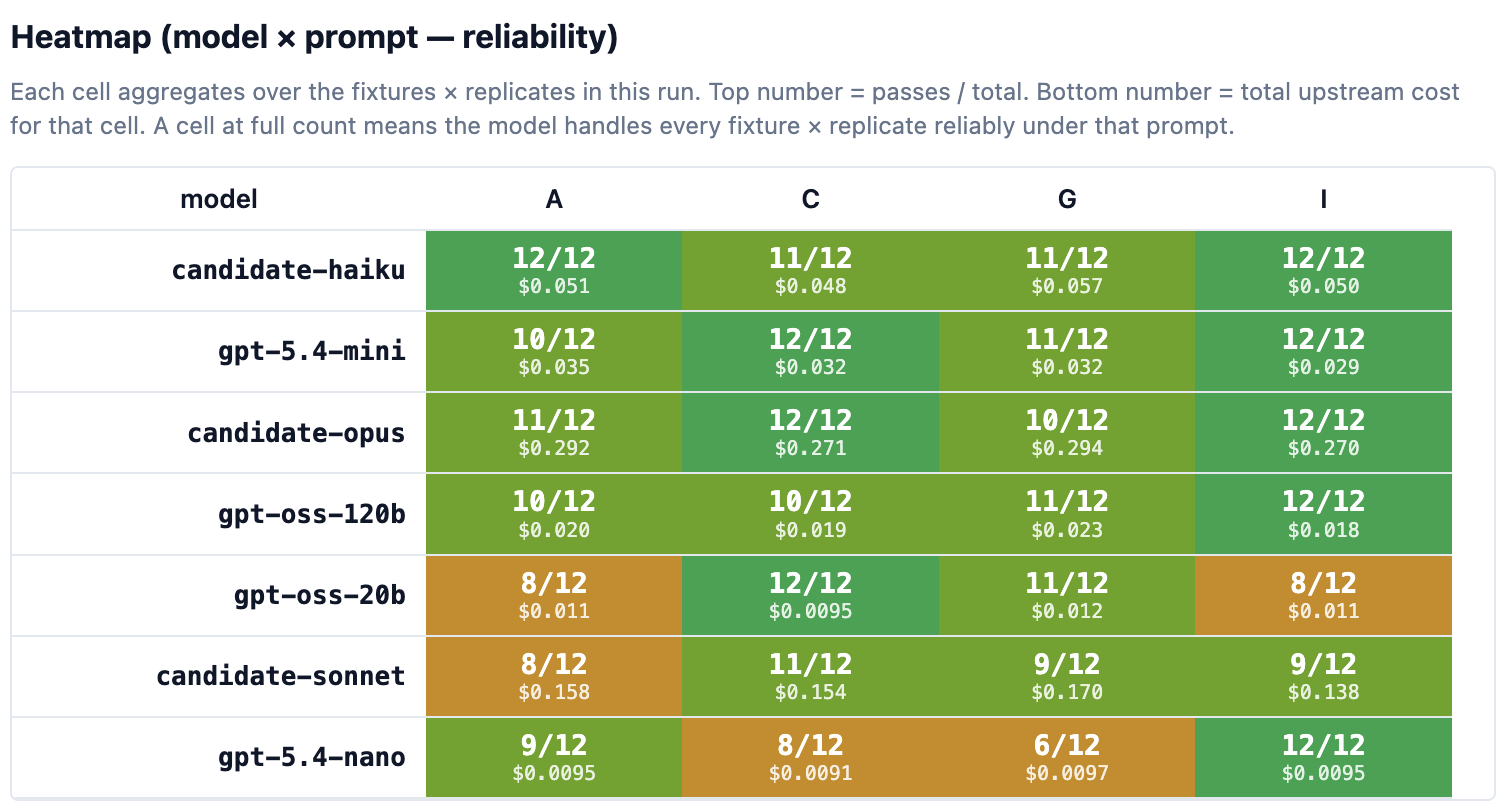
Crucially, we don't need a model to work with every prompt. In production each model runs against the single prompt that suits it best. The right question is: how many model × prompt combinations hit a clean 12/12 across all four households - and what do they cost?
Nine combinations did. Plotted on cost and latency, they tell a sharper story than any average pass-rate:
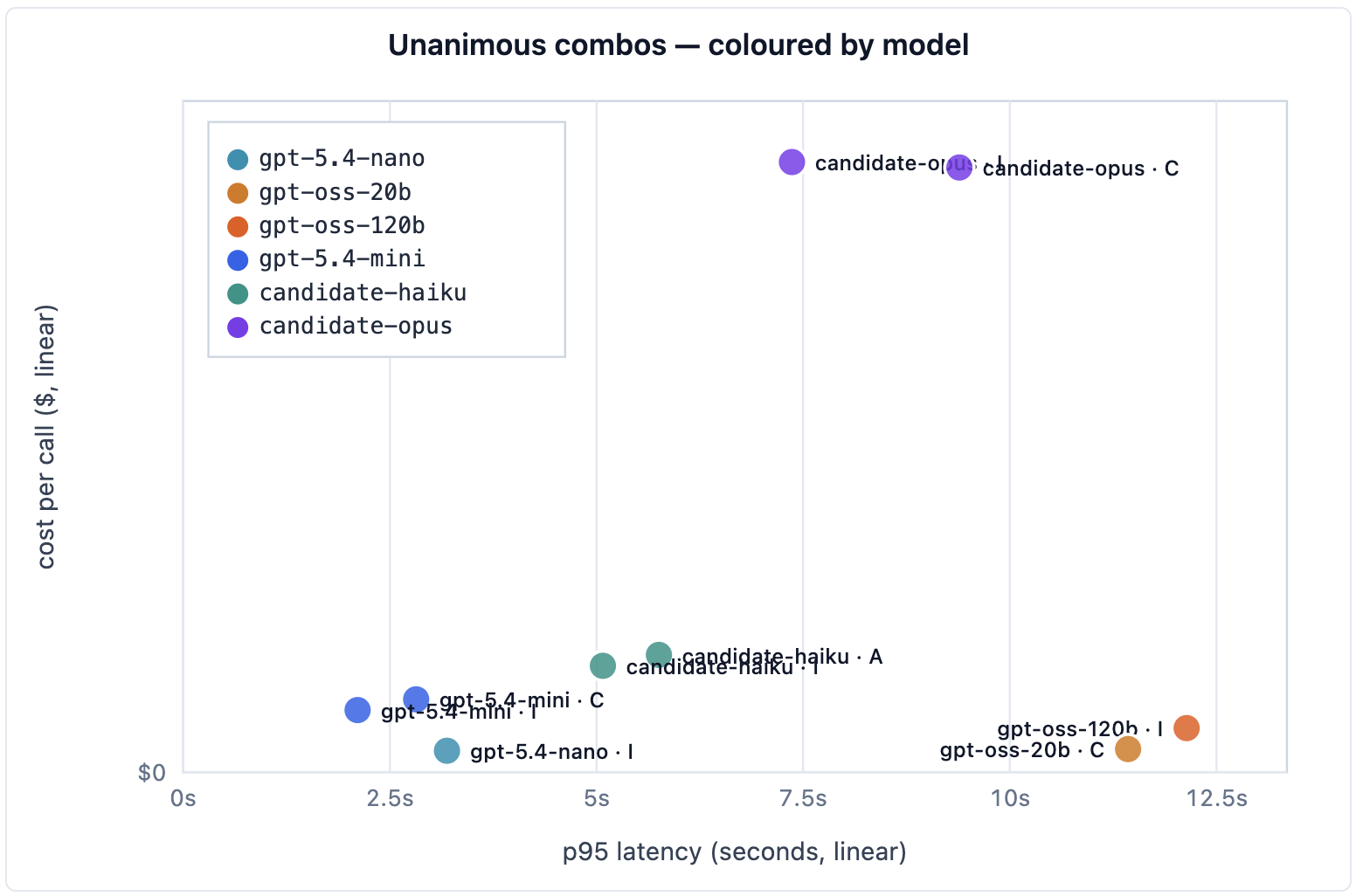
GPT-5.4-nano · I is the surprise winner. Once paired with the validator-mirror prompt, nano clears 12/12 across every household - including dravecky-skov - at a median cost of $0.0007 per call and ~3s p95 latency. Across all four prompts nano averaged only 35/48, but that average is the wrong frame: with the right prompt, this is the cheapest passing model on the menu and ~30x cheaper than Opus.
GPT-5.4-mini · C and · I are the safe pragmatic default. Two unanimous combinations, ~$0.0024 per call, ~2s median latency. Roughly 9x cheaper than Opus for the same structural result, and far less prompt-sensitive than nano if you only want to maintain one configuration.
Claude Opus · A and · C earn the premium only on the hardest edges. Two unanimous combinations at $0.0212 per call and 6.4s median latency. On the easy households Opus is paying ~30x for a result nano already gets right. Where it pulls ahead is the harder edges of dravecky-skov where nano stumbles on the wrong prompt.
Claude Haiku · A and · I are unanimous too, with a catch. Haiku wraps its JSON in markdown fences every single time. The evaluator was generous and stripped the fence; production would need a response-cleaning step, and that becomes part of the operating cost.
The broader lesson is not "always use the smallest model." It is "measure the task." If a workflow is standardised, bounded, and backed by validators, you can often choose a model that is good enough rather than the largest one on the menu.
Every model in the shootout produced invented recipes - names that sound real but aren't tied to anything in the household's actual recipe library. A plan can score 100% on every validator and still be worthless to a user if "Polenta-Ost Gratin" isn't a recipe they have or want.
The next contract revision will add a recipe_grounded rule: every
recipe ID in the plan must resolve to a real recipe in Madklar's (or
the household's) library. Once we have grounding, additional criteria
become possible - budget, prep time, culinary attractiveness - and the
question shifts from "which model produces a structurally-valid plan?"
to "which model produces a plan a household will actually cook and eat?"
That progression is itself the point worth keeping. The validator became a product spec in disguise: once the rules were explicit enough to score a model, they were also explicit enough to describe what Madklar should guarantee in production - correct dates, real attendance, dietary safety, language match, grounded recipes. The shootout stopped being a side experiment and became a sharper definition of the product.
For today's question, GPT-5.4-nano is the pragmatic default: fast, strict about JSON, much cheaper than Opus, and still reliable on the hardest household. The model market will keep moving and that answer will change. The contract, the fixtures, and the validator won't, unless our business logic changes.
If you're running an AI-backed workflow today, three questions matter more than any benchmark someone else publishes:
Get those three right and the model question answers itself every time the market moves.
There's a common sequence of events in growing businesses: the team gets busy, someone can't keep up, so you hire …
Start with a conversation. We'll help you figure out if there's something worth shaping, building, or simplifying - and tell you honestly when there isn't.
Book a conversation